
minghf85/AIFE
AI 虚拟桌宠伙伴系统,将会持续更新
Python
16
4
本项目实现了一个基于AI的虚拟桌宠伙伴系统,结合了大型语言模型和语音合成技术,提供低延迟的实时对话体验,轻量化,全python。
功能特点#
- 双引擎并行:同时集成ollama和GPTsovits引擎(api_v2,具体参考GPTsovits),实现高效稳定的对话处理
- 低延迟对话:优化语音识别和合成流程,实现快速响应
- Live2D支持:支持Live2D v3模型
- 实时语音同步:通过mic_lipsync模块实现口型与语音的同步
- 模块化设计:包含LLM、TTS、STT等独立模块,便于扩展和维护
前置条件#
对应功能需要的条件,自选是否需要安装,文末有对应链接。
- 语音识别:启动加载模型时会下载Huggingface模型,需要科学上网
- 语音合成:已安装GPT_sovits0821版本,将本项目的api_v2.py复制替换掉GPT_sovits根目录的api_v2.py(增加了打断播放功能)
- 本地LLM:ollama,详细安装和运行下载模型请自行搜索
部署使用#
安装依赖:
pip install -r requirements.txt配置环境变量.env(不需要引号):
#如果要使用deepseek的话 DEEPSEEK_API_KEY = sk-xxxxxxxxxxxxxxxxx运行主程序:
python main.py页面介绍
live2d模型
本项目提供两个开源的live2d模型Haru和Hiyori,若使用自己的模型需要先标准化,请自行备份好原来的文件。
语音识别
选择你的麦克风等,第一次加载模型需要从huggingface下载模型,需科学上网。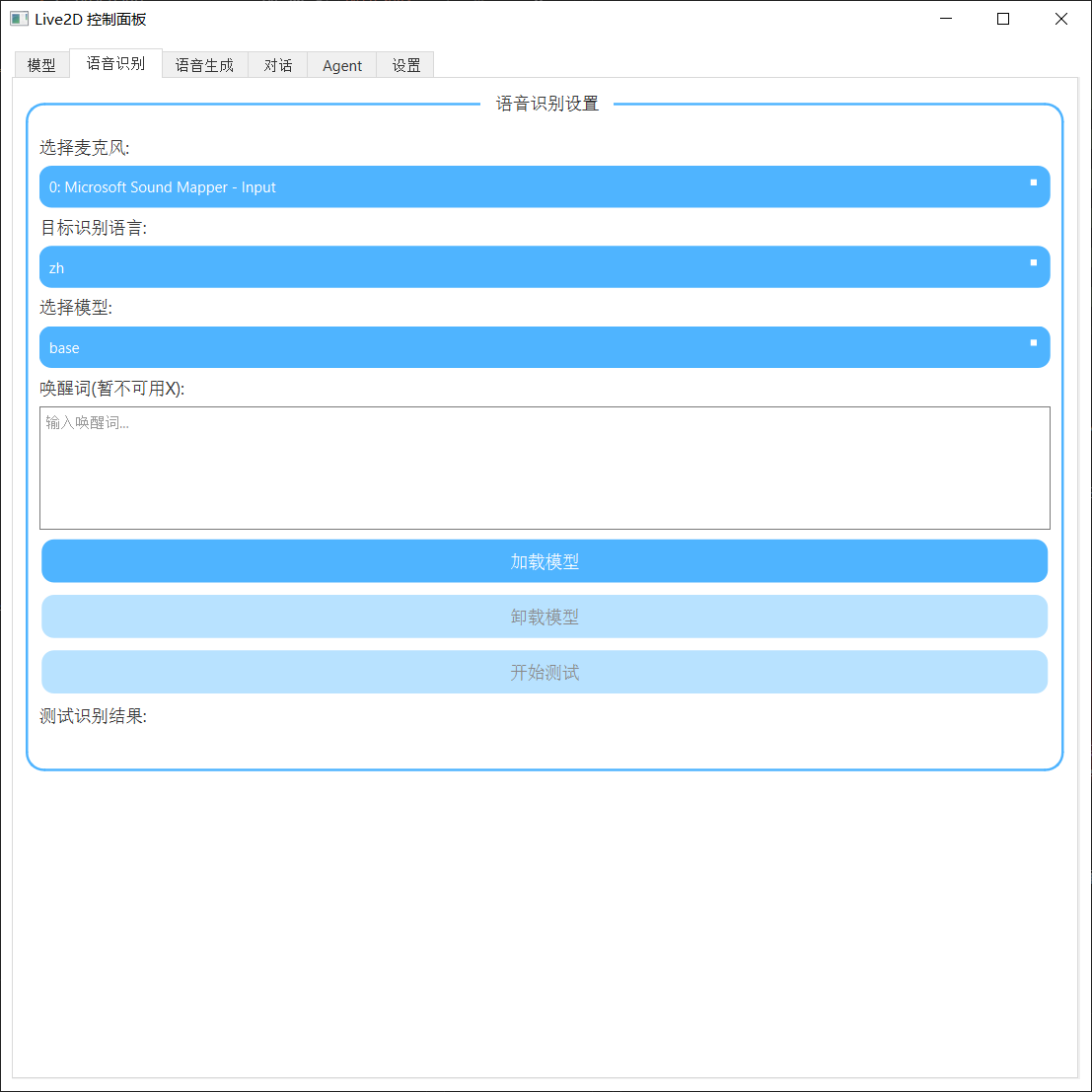
语音生成 gptsovits设置参数请参考gptsovits项目或搜索
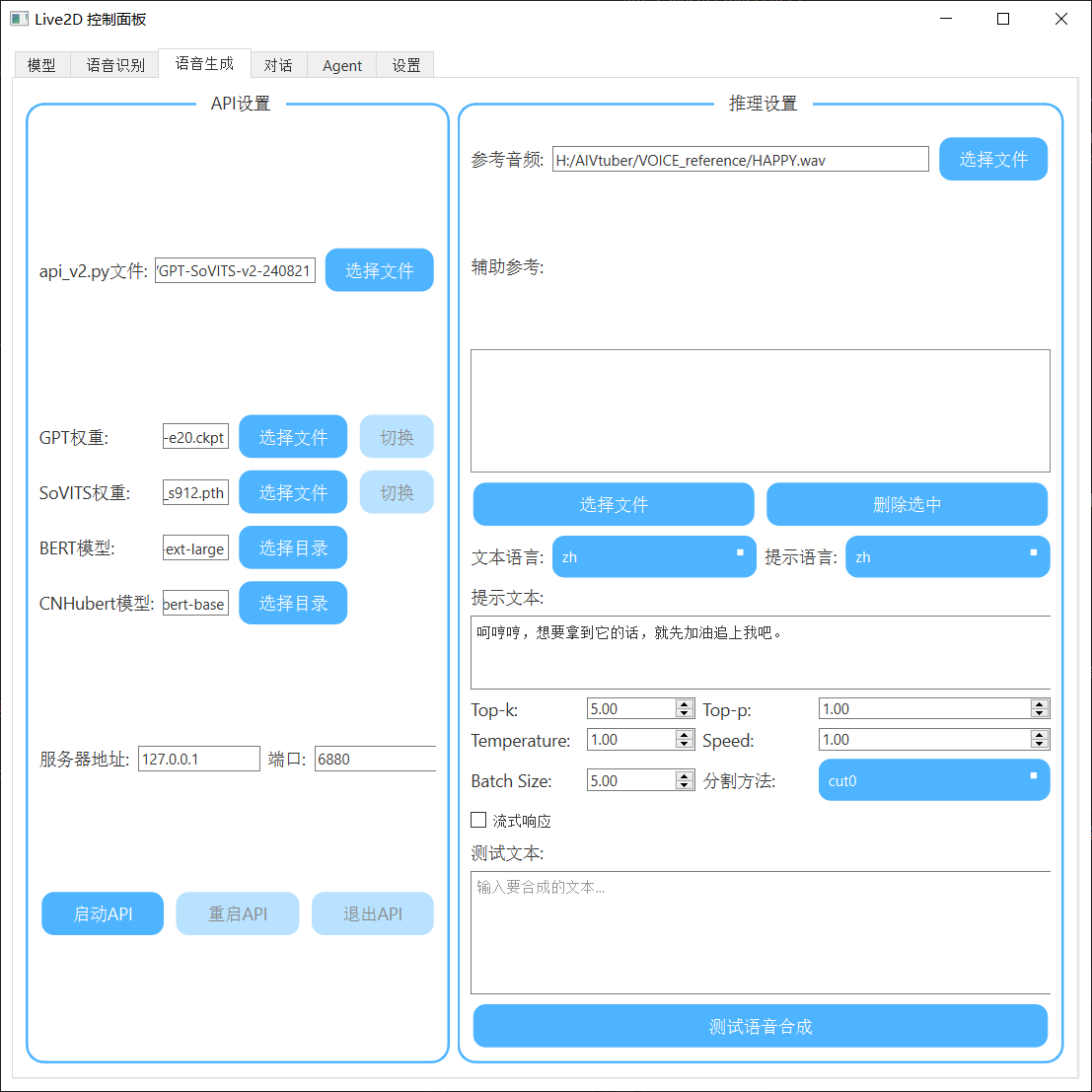
- 要在此项目上启动api的话需要选择GPTsovits根目录和对应模型路径。
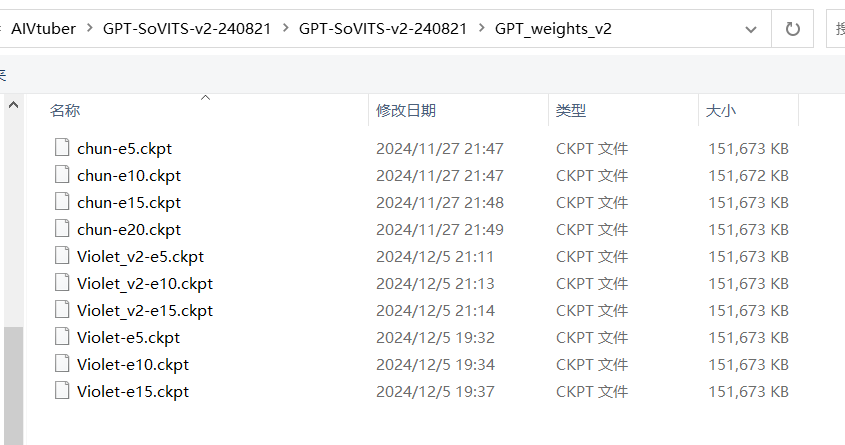
- GPT权重路径参考
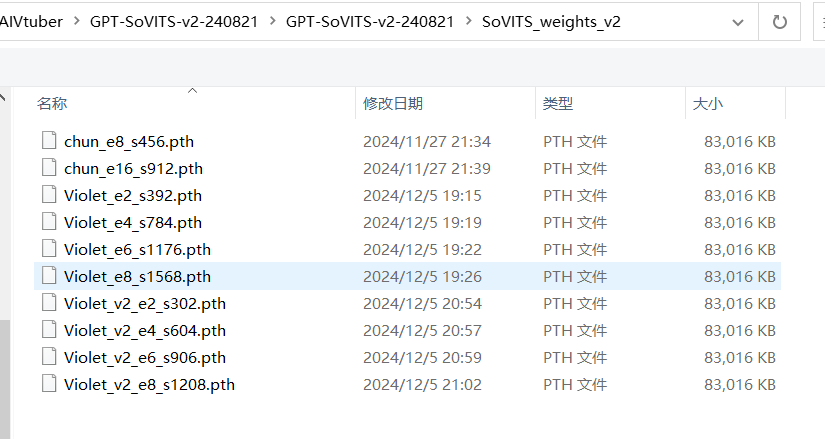
- Sovits权重路径参考
- BERT和CNHubert参考
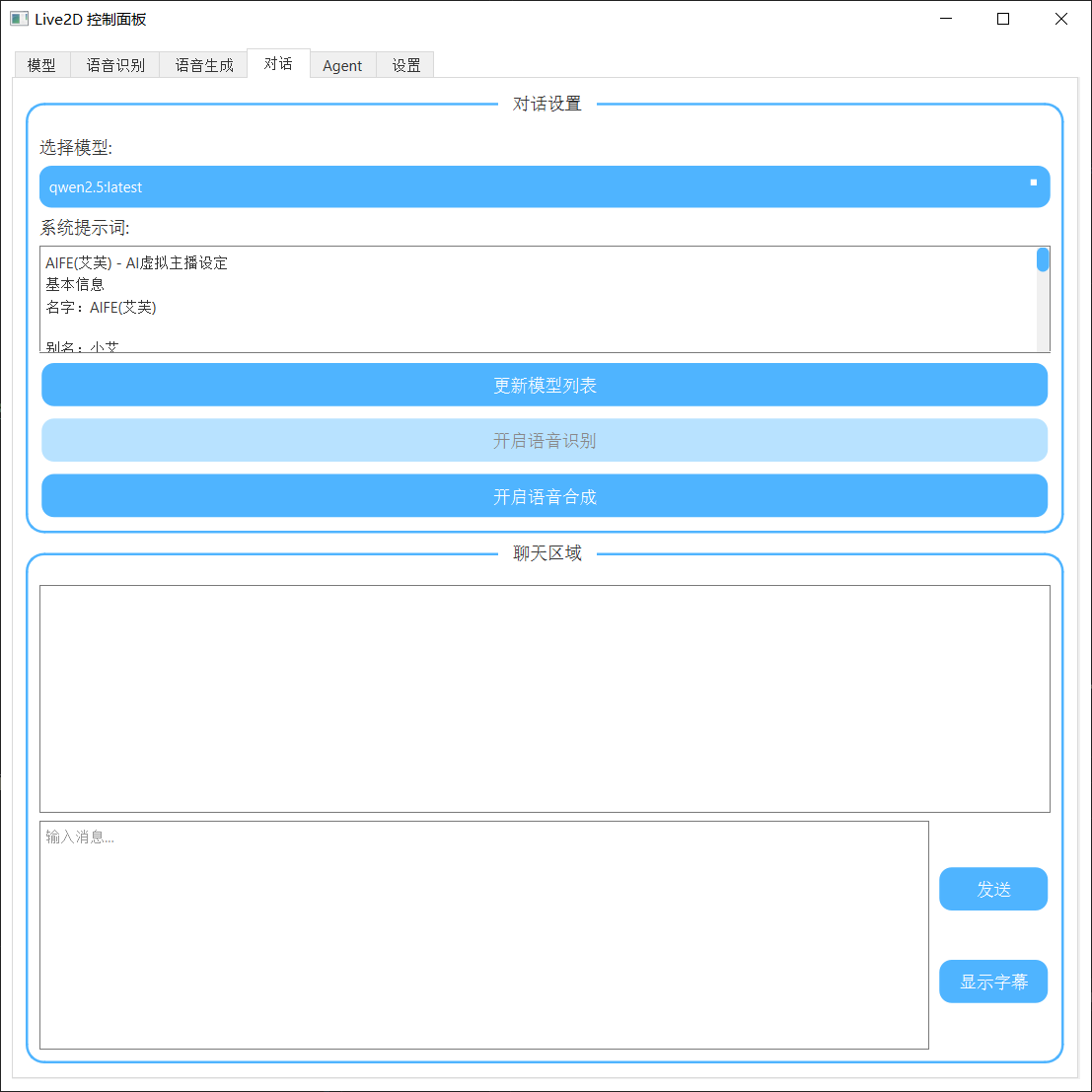
对话
设置
- 可以保存你的部分配置
演示:
- 暂时还没出完整教学视频,一个简单的演示视频
- 主界面想和模型现实
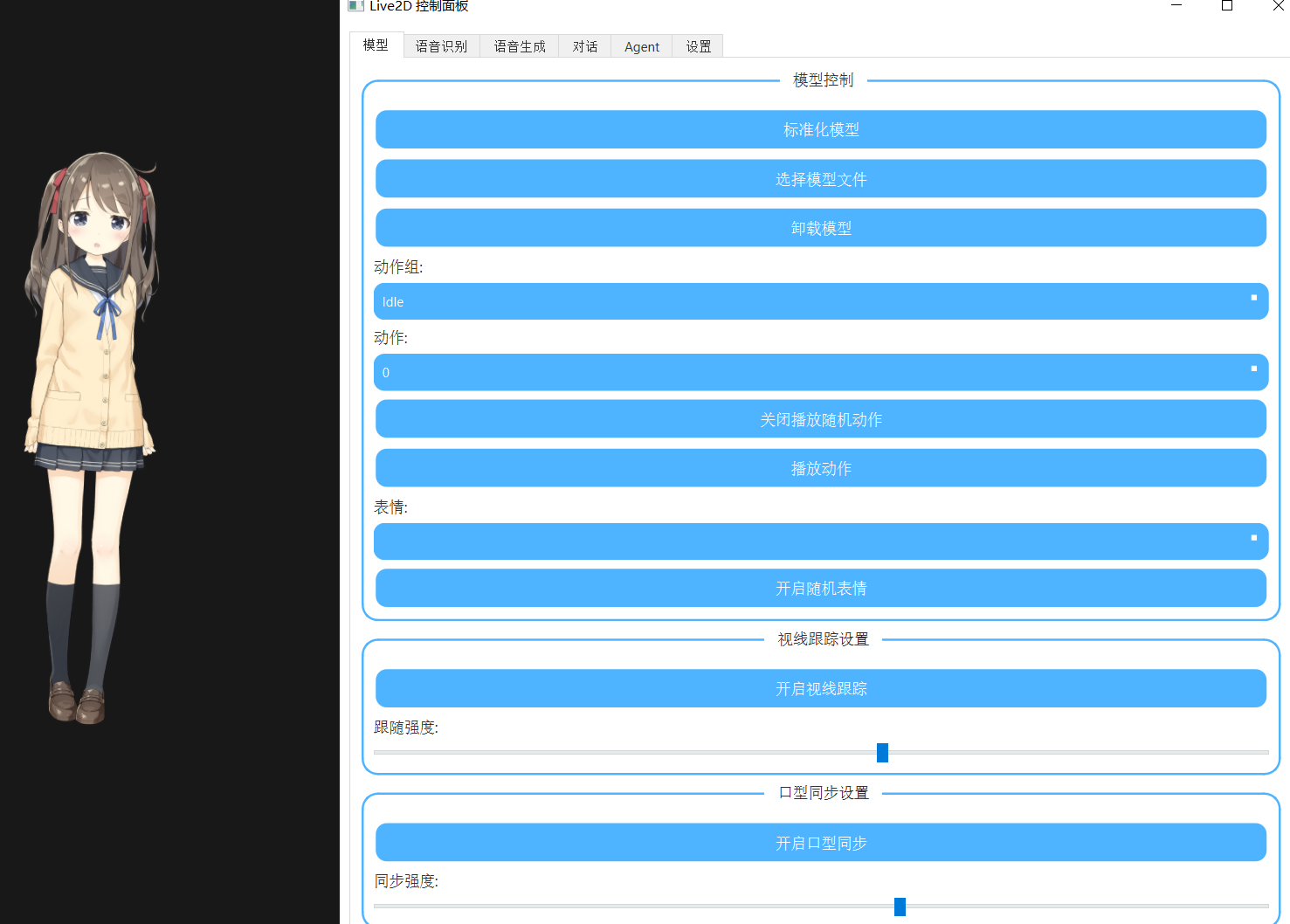
- 暂时还没出完整教学视频,一个简单的演示视频
事项#
- GPTsovits 对接
- deepseek api对接
- stream流语音合成并行处理
- 接入kokoro语音合成
- 记忆实现
- 游戏性、互动性、情绪性、成长性
- LLM人物姿态驱动
鸣谢#
本项目使用了以下开源库和资源:
- live2d-py:提供live2d角色模型加载和动画支持
- ollama:用于语言模型推理
- GPTsovits:用于语音合成
- realtimeSTT:用于音频实时识别
- 其他依赖库:详见requirements.txt
特别感谢所有开源社区贡献者和项目维护者。
项目结构#
.
├── ControlPanel.py # 控制面板
├── Live2DWindow.py # Live2D显示窗口
├── LLM.py # 语言模型模块
├── STT.py # 语音识别模块
├── TTS.py # 语音合成模块
├── mic_lipsync.py # 口型同步模块
├── main.py # 主程序
├── Haru/ # Haru角色资源
├── hiyori/ # hiyori角色资源
└── logs/ # 日志记录
注意事项#
- 建议环境为python为3.12,其余版本未测试
- 首次运行时可能需要下载模型文件,请保持网络连接
- 建议使用NVIDIA GPU以获得最佳性能,根据自己显存分配各个功能