
RAG-Retrieval-Augmented Generation 论文精读#
论文链接:RAG
阅读之前的初步理解:RAG通过将文档分段分块,然后向量化这些文档片段,即embedding,使用特殊的框架如Faiss、Elasticsearch保存和加载。用户与LLM对话,输入的文本也会被向量化,通过向量检索(余弦相似度),找到与用户输入最相关的文档片段,然后将这些片段作为上下文传递给LLM进行生成。
下面我会按照论文原有结构进行解读,结合自己的理解,逐步深入。
Abstract#
这篇论文探讨了一种结合参数化与非参数化记忆的检索增强生成模型(RAG),其核心内容可总结如下:
研究背景
传统预训练语言模型虽能存储知识,但在需要精确调用和更新知识的任务中表现不足,且缺乏决策溯源能力。
现有非参数化记忆(如外部知识库)的模型多局限于抽取式任务,生成任务中的应用尚未充分探索。
方法创新
提出RAG框架:
参数化记忆:预训练的序列到序列(
seq2seq)模型(如BART)。非参数化记忆:基于
Wikipedia构建的稠密向量索引,通过预训练检索器动态访问。
两种检索模式:
全局检索
Rag-Sequence:整个生成过程使用同一组检索文档。局部检索
Rag-Token:每个生成步骤可动态选择不同文档。
实验结果
在开放域问答(QA)任务中,RAG超越纯参数化模型和传统检索-抽取架构,刷新三项任务的SOTA。
生成任务中,RAG相比纯参数化模型输出更具事实性、多样性和细节丰富性,且能减少幻觉。
意义
- 为知识密集型任务提供通用解决方案,同时缓解了纯参数化模型的知识更新困难与决策不可溯源问题。
关键贡献:首次将检索增强生成扩展到通用语言生成任务,通过结合双记忆系统提升生成质量与事实准确性。
1. Introduction#
预训练大语言模型可以不依靠外部存储就能展现出很好的知识存储能力,但是由于训练结构和流程的固化,不能轻松更新扩展知识记忆,并且会存在幻觉问题。
幻觉是指模型生成的文本与真实世界不符的现象,通常是由于模型在训练时接触到的知识有限或不准确所导致的。
RAG之前的工作如REALM-Retrieval-Augmented Language Model Pre-Training和ORQA-Open Retrieval-Augmented Generation,主要集中开放域抽取式问答任务上,而RAG则将其扩展到生成任务中。
开放域抽取式问答(Open-Domain Extractive Question Answering, ODQA) 是自然语言处理(NLP)中的一项核心任务,旨在从大规模非结构化文本集合(如维基百科)中直接抽取答案片段,以回答用户提出的开放领域问题。
作者们提出一种通用微调方法即RAG,结合了参数化和非参数化记忆的seq2seq模型,允许模型在生成过程中动态地从外部知识库中检索信息,然后讲了一些优点和结果。
2. Method#
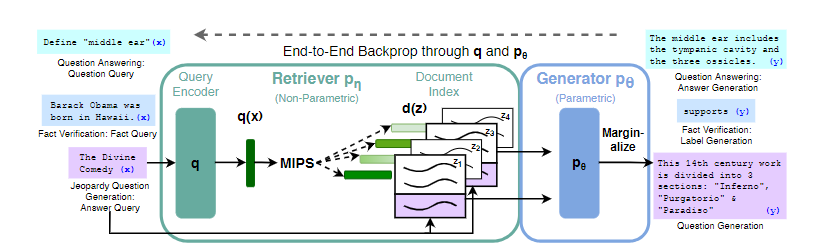
变量说明(先知道是啥就行)
x: 输入序列z: 文本文档y: 目标答案序列检索器的参数化分布 \( p_{\eta}(z|x) \)
输入:问题序列 \( x \)(如“谁发明了电话?”)。
输出:相关文档 \( z \)(如维基百科段落)。
参数:\( \eta \)(检索模型的权重,如神经检索器的编码器参数)。
作用:计算 \( x \) 与候选文档 \( z \) 的相关性分数,选择最匹配的文档。
生成器的参数化分布 \( p_{\theta}(y|x,z,y_{1:i-1}) \)
输入:问题 \( x \) + 检索文档 \( z \) + 已生成答案前缀 \( y_{1:i-1} \)(如“电话的发明者是”)。
输出:下一个词 \( y_i \)(如“贝尔”)。
参数:\( \theta \)(生成模型的权重,如BART或T5的解码器参数)。
作用:基于检索知识 \( z \) 和上下文 \( y_{1:i-1} \),预测答案的下一词。
2.1 Models#
RAG-Sequence:
RAG-Token